K8s容器一直重启问题排查
问题
昨天有个客户反馈服务不可访问,查看服务日志发现dns无法解析,通过kubectl查看kube-dns 这个pod一直在重启,客户只反馈了这一个问题,如图:
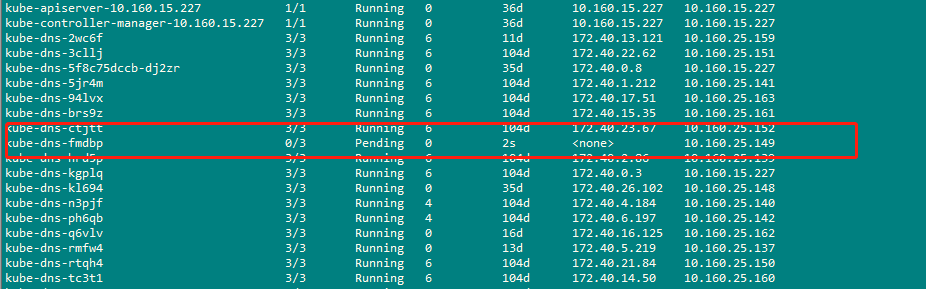
过了一会后发现kube-dns灾厄已经恢复,但是kube-flannel这个pod又开始一直重启。
根据自己以往的经验还以为是路由出了什么问题,所以在排查路由方面浪费了一些时间,
排查一段时间路由后未发现异常,随后想到查看有问题机器的kubelet日志,如下
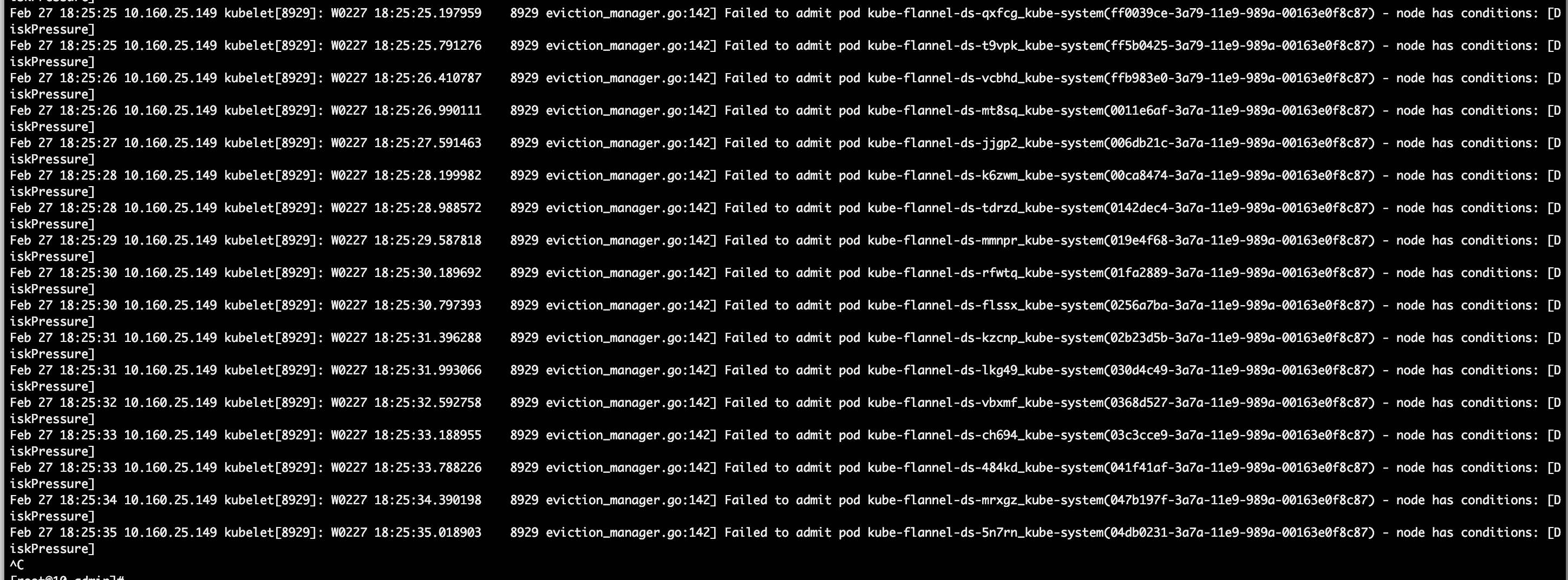
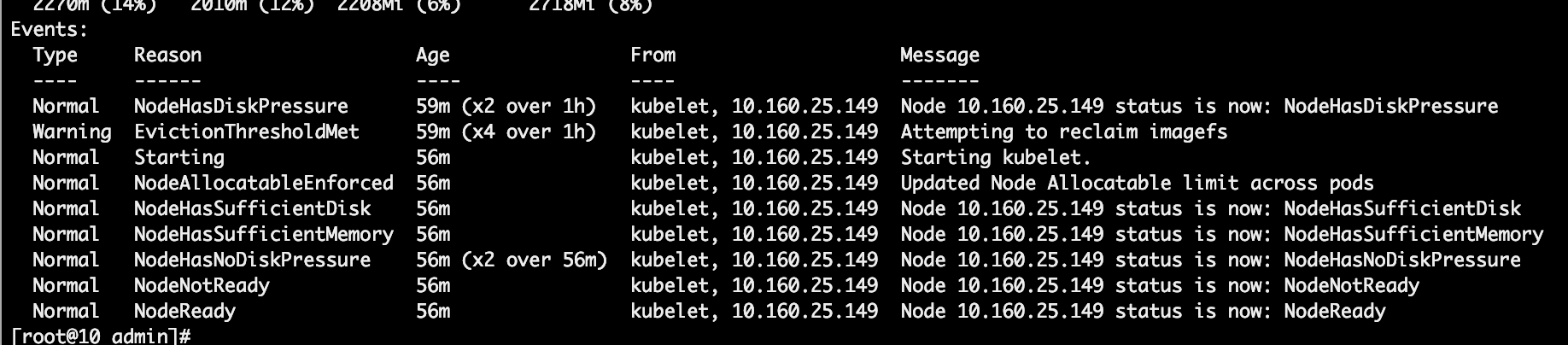
describe node的Events如下:
解决
通过日志可以发现是磁盘满导致的原因,但在当时看到问题时只是根据经验以为是路由有问题(只能说是学艺不精),
但是我还没来得及查看磁盘,就补客户给清理过,而且客户还顺手把机器给重启了,机器启动后一切就恢复正常
排查
后来上网搜索相关错误字段,随后阅读相关文章以及查看k8s代码,发现k8s有一个Eviction Manager的机制,如下图:
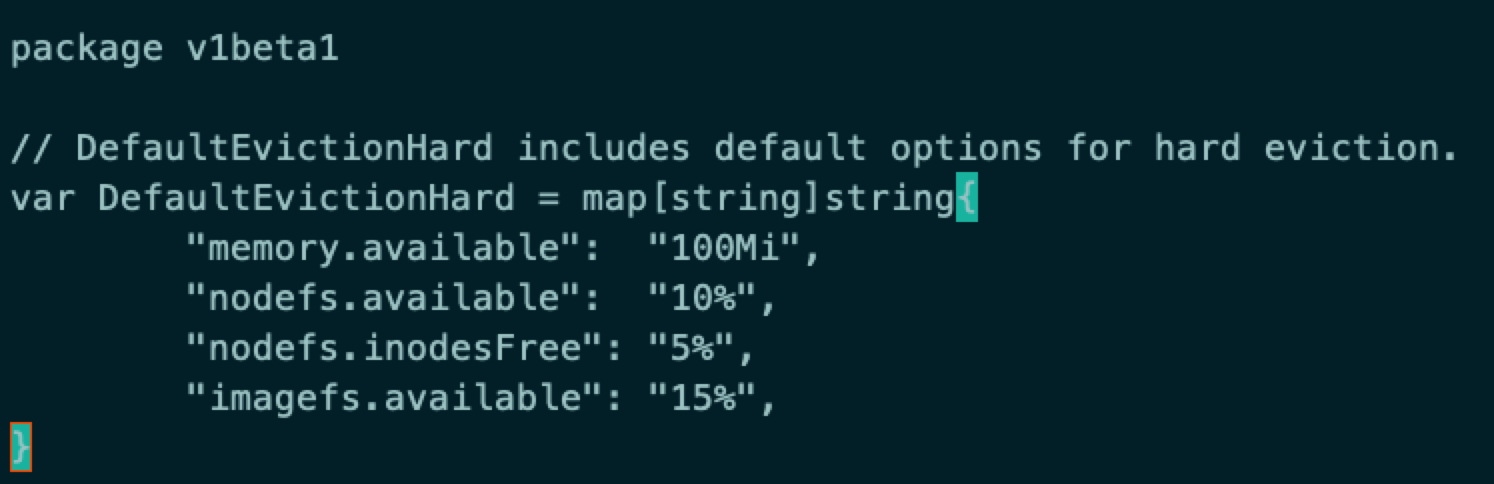
如果在启动k8s时没有设置Eviction Thresholds(驱逐阈值),k8s将按代码里(上图)默认的值执行
但是通过可看kubelet日志发现,前一天的时候就已经发现有相关报错,那时候报的是Eviction image 全是错误状态(没有驱逐成功),这一点也很好理解,因为当所有的镜像都在使用(都被容器占用)时,删除镜像是失败的
那为什么到后来就已经开始是pod被驱逐呢?
后来又从k8s的代码里发现了两个概念 Soft Eviction Thresholds(软驱逐) 和 Hard Eviction Thresholds (硬驱逐)
这两个概念可以查看 这里
总结
简单一句话总结就是:当软驱逐失败时会强制执行硬驱逐
所以出现问题的时候就是,先软驱逐所有的image失败(因为从阈值看最先达到镜像的设置值),后开始驱逐相关pod,具体驱逐pod的机制在 这里 也有详细描述。
预防
到这里问题就已经全部搞清楚,所以为了预防此类事故再次发生,建议将磁盘报警监控设置到80%以下,如果有报警需要及时处理。
