Kubernetes Eviction Manager工作机制分析
摘要
为了极限的压榨资源,很多时候Kubernetes集群会运行一些Best-Effort Task,这样就会存在资源超配的情况,Kubernetes是如何控制Node上资源的使用,在压榨资源使用的同时又能保证Node的稳定性?本文就为你介绍其背后运行机制。我的下一篇博文,会对Kubelet Eviction Manager进行源码分析,感兴趣的同学可以关注。
研究过Kubernetes Resource QoS的同学,肯定会有一个疑问:QoS中会通过Pod QoS和OOM Killer进行资源的回收,当发生资源紧缺的时候。那为什么Kubernetes会再搞一个Kubelet Eviction机制,来做几乎同样的事呢?
首先,我们来谈一下kubelet通过OOM Killer来回收资源的缺点:
- System OOM events本来就是对资源敏感的,它会stall这个Node直到完成了OOM Killing Process。
- 当OOM Killer干掉某些containers之后,kubernetes Scheduler可能很快又会调度一个新的Pod到该Node上或者container 直接在node上restart,马上又会触发该Node上的OOM Killer启动OOM Killing Process,事情可能会没完没了的进行,这可不妙啊。
我们再来看看Kubelet Eviction有何不同:
- Kubelet通过pro-actively监控并阻止Node上资源的耗尽,一旦触发Eviction Signals,就会直接Fail一个或者多个Pod以回收资源,而不是通过Linux OOM Killer这样本身耗资源的组件进行回收。
- 这样的Eviction Signals的可配置的,可以做到Pro-actively。
- 另外,被Evicted Pods会在其他Node上重新调度,而不会再次触发本Node上的再次Eviction。
下面,我们具体来研究一下Kubelet Eviction Policy的工作机制。
- kubelet预先监控本节点的资源使用,并且阻止资源被耗尽,这样保证node的稳定性。
- kubelet会预先Fail N(>= 1)个Pod以回收出现紧缺的资源。
- kubelet会Fail一个Node时,会将Pod内所有Containners都kill掉,并把PodPhase设为Failed。
- kubelet通过事先人为设定Eviction Thresholds来触发Eviction动作以回收资源。
Eviction Signals
支持如下Eviction Signals:
| Eviction Signal | Description |
|---|---|
| memory.available | memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
| nodefs.available | nodefs.available := node.stats.fs.available |
| nodefs.inodesFree | nodefs.inodesFree := node.stats.fs.inodesFree |
| imagefs.available | imagefs.available := node.stats.runtime.imagefs.available |
| imagefs.inodesFree | imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
- kubelet目前支持一下两种filesystem,其中imagefs为可选的。Kubelet通过cAdvisor来自动发现这些filesystem。
- nodefs - Kubelet用来存储volume,logs等数据。
- imagefs - 容器运行时(dockerd/rkt等)用来存放镜像和容器的Writable Layer。
Eviction Thresholds
前面也提到,kubelet通过事先人为设定Eviction Thresholds来触发Eviction动作以回收资源。
- Eviction Thresholds的形式为:
- quantity支持绝对值和相对百分比两种形式,比如:
- memory.available<10%
- memory.available<1Gi
Soft Eviction Thresholds
Soft Eviction Thresholds是什么意思?
它指的是,当Eviction Signal中值达到Soft Eviction Thresholds配置的值时,并不会马上触发Kubelet去Evict Pods,而是会等待一个用户配置的grace period之后,再触发。相关的配置有三个,如下:
- eviction-soft - (e.g. memory.available<1.5Gi) 触发Soft Eviction的Evication Signal阈值。
- eviction-soft-grace-period - (e.g. memory.available=1m30s) 当Eviction Signal的值达到配置eviction-soft值后,需要等待grace period,注意这期间,每10s会重新获取监控数据并维护Threshold的值。如果grace period最后一次监控数据仍然触发了阈值,才会再触发Evict Pods。这个参数就是配置这个grace period的。
- eviction-max-pod-grace-period - (e.g. memory.available=30s) 这个是配置Evict Pods时,Pod Termination的Max Grace Period。如果待Evict的Pod指定了pod.Spec.TerminationGracePeriodSeconds,则取min(eviction-max-pod-grace-period, pod.Spec.TerminationGracePeriodSeconds)作为Pod Termination真正的Grace Period。
因此,从kubelet监控到的Eviction Signal达到指定的Soft Eviction Thresholds开始,到Pod真正被Kill,总共所需要的时间为:sum(eviction-soft-grace-period + min(eviction-max-pod-grace-period,pod.Spec.TerminationGracePeriodSeconds))
Hard Eviction Thresholds
理解了Soft Eviction Thresholds,那么Hard Eviction Thresholds就很简单了,它是指:当Eviction Signal中值达到Hard Eviction Thresholds配置的值时,会立刻触发Kubelet去Evict Pods,并且也不会有Pod Termination Grace Period,而是立刻kill Pods,即使待Evict的Pod指定了pod.Spec.TerminationGracePeriodSeconds。
总之,Hard Eviction Thresholds就是来硬的,一旦触发,kubelet立刻马上kill相关的pods。
因此,kubelet关于Hard Eviction Thresholds的配置也只有一个:
- eviction-hard - (e.g. memory.available<1Gi) 这个值,要设置的比eviction-soft更低才有意义。
Eviction Monitoring Interval
kubelet会通过监控Eviction Signal的值,当达到配置的阈值时,就会触发Evict Pods。
kubelet对应的监控周期,就通过cAdvisor的housekeeping-interval配置的,默认10s。
Node Conditions
当Hard Eviction Thresholds或Soft Eviction Thresholds被触及后,Kubelet会将对应的Eviction Signals映射到对应的Node Conditions,其映射关系如下:
| Node Condition | Eviction Signal | Description |
|---|---|---|
| MemoryPressure | memory.available | Available memory on the node has satisfied an eviction threshold |
| DiskPressure | nodefs.available, nodefs.inodesFree, imagefs.available, or imagefs.inodesFree | Available disk space and inodes on either the node’s root filesystem or image filesystem has satisfied an eviction threshold |
kubelet映射了Node Condition之后,会继续按照–node-status-update-frequency(default 10s)配置的时间间隔,周期性的与kube-apiserver进行node status updates。
Oscillation of node conditions
想象一下,如果一个Node上监控到的Soft Eviction Signals的值,一直在eviction-soft水平线上下波动,那么Kubelet就会将该Node对应的Node Condition在true和false频繁切换。这可不是什么好事,它可能会带来kube-scheduler做出错误的调度决定。kubelet是怎么处理这种情况的呢?
很简单,Kubelet通过添加参数eviction-pressure-transition-period(default 5m0s)配置,使Kubelet在解除由Evicion Signal映射的Node Pressure之前,必须等待这么长的时间。
因此,逻辑就变成这样了:
- Soft Evction Singal高于Soft Eviction Thresholds时,Kubelet还是会立刻设置对应的MemoryPressure Or DiskPressure为True。
- 当MemoryPressure Or DiskPressure为True的前提下,发生了Soft Evction Singal低于Soft Eviction Thresholds的情况,则需要等待eviction-pressure-transition-period(default 5m0s)配置的这么长时间,才会将condition pressure切换回False。
一句话总结:Node Condition Pressure成为True容易,切换回False则要等eviction-pressure-transition-period。
Eviction of Pods
Kubelet的Eviction流程概括如下:
- 在每一个监控周期内,如果Eviction Thresholds被触及,则:
- 获取候选Pod
- Fail the Pod
- 等待该Pod被Terminated
- 如果该Pod由于种种原因没有被成功Terminated,Kubelet将会再选一个Pod进行Fail Operation。其中,Fail Pod的时候,Kubelet是通过调用容器运行时的KillPod接口,如果接口返回True,则认为Fail Pod成功,否则视为失败。
Eviction Strategy
kubelet根据Pod的QoS Class实现了一套默认的Evication策略,内容见我的另外一篇博文Kubernetes Resource QoS机制解读中介绍的“如何根据不同的QoS回收Resource”,这里不再赘述。
下面给出Eviction Strategy的图解:
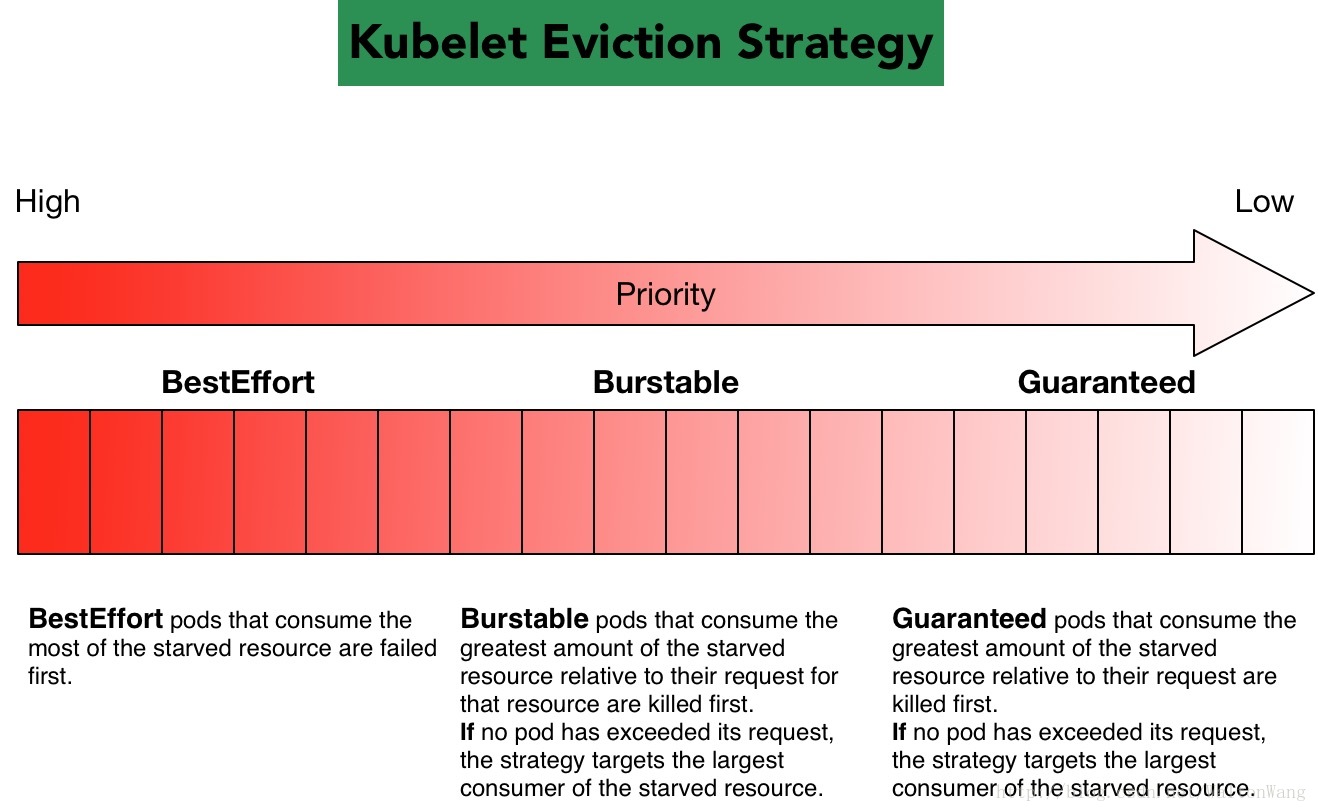
Minimum eviction reclaim
有些情况下,eviction pods可能只能回收一小部分的资源就能使得Evication Signal的值低于Thresholds。但是,可能随着资源使用的波动或者新的调度Pod使得在该Node上很快又会触发evict pods的动作,eviction毕竟是耗时的动作,所以应该尽量避免这种情况的发生。
Kubelet是通过–eviction-minimum-reclaim(e.g. memory.available=0Mi,nodefs.available=500Mi,imagefs.available=2Gi)来控制每次Evict Pods后,Node上对应的Resource不仅要比Eviction Thresholds低,还要保证最少比Eviction Thresholds低–eviction-minimum-reclaim中配置的数量。
Node OOM Behavior
正常情况下,但Node上资源利用率很高时,Node的资源回收是会通过Kubelet Eviction触发完成。但是存在这么一种情况,Kubelet配置的Soft/Hard memory.available还没触发,却先触发了Node上linux kernel oom_killer,这时回收内存资源的请求就被kernel oom_killer处理了,而不会经过Kubelet Eviction去完成。
我的博文Kubernetes Resource QoS机制解读中介绍过,Kubelet根据Pod QoS给每个container都设置了oom_score_adj,整理如下:
| Quality of Service | oom_score_adj |
|---|---|
| Guaranteed | -998 |
| BestEffort | 1000 |
| Burstable | min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
oom_killer根据container使用的内存占Node总内存的百分比计算得到该container的oom_score,然后再将该oom_sore和前面对应的oom_score_adj相加作为最终的oom_score,Node上所有containers的最终oom_score进行排名,将oom_score得分最高的container kill掉。通过如此方式进行资源回收。
oom_killer这样做的目标就是干掉QoS低的又消耗最多内存(相对request值)的容器首先被kill掉,如此回收内存。
不同于Kubelet Evict Pods的是,Node OOM Behavior存在一个缺点:如果Pod中某个容器被oom_killer干掉之后,会根据该容器的RestartPolicy决定是否restart这个容器。如果这是个有问题的容器,restart之后,可能又很快消耗大量内存进而触发了再次Node OOM Behavior,如此循环反复,该Node没有真正的回收到内存资源。
Scheduler
前面提到,Kubelet会定期的将Node Condition传给kube-apiserver并存于etcd。kube-scheduler watch到Node Condition Pressure之后,会根据以下策略,阻止更多Pods Bind到该Node。
| Node Condition | Scheduler Behavior |
|---|---|
| MemoryPressure | No new BestEffort pods are scheduled to the node. |
| DiskPressure | No new pods are scheduled to the node. |
总结
- Kubelet通过Eviction Signal来记录监控到的Node节点使用情况。
- Eviction Signal支持:memory.available, nodefs.available, nodefs.inodesFree, imagefs.available, imagefs.inodesFree。
- 通过设置Hard Eviction Thresholds和Soft Eviction Thresholds相关参数来触发Kubelet进行Evict Pods的操作。
- Evict Pods的时候根据Pod QoS和资源使用情况挑选Pods进行Kill。
- Kubelet通过eviction-pressure-transition-period防止Node Condition来回切换引起scheduler做出错误的调度决定。
- Kubelet通过–eviction-minimum-reclaim来保证每次进行资源回收后,Node的最少可用资源,以避免频繁被触发Evict Pods操作。
- 当Node Condition为MemoryPressure时,Scheduler不会调度新的QoS Class为BestEffort的Pods到该Node。
- 当Node Condition为DiskPressure时,Scheduler不会调度任何新的Pods到该Node。
作者:WaltonWang
来源:CSDN
原文:https://blog.csdn.net/WaltonWang/article/details/55804309
版权声明:本文为博主原创文章,转载请附上博文链接!
