灵雀云K8s集群对接Prometheus
安装helm
安装helm
docker run -ti --rm -v /usr/local/bin/:/var/log/abc index.alauda.cn/claas/helm:v2.10.0-rc.2 sh -c "cp /systembin/helm /var/log/abc"安装chart_repo源(我自己的平台已经安装,所以不需要操作)
docker run -d \
-p 8088:8080 \
-e PORT=8080 \
-e DEBUG=1 \
-e STORAGE="local" \
-e STORAGE_LOCAL_ROOTDIR="/data" \
-e BASIC_AUTH_USER="chartmuseum" \
-e BASIC_AUTH_PASS="chartmuseum" \
-v /data:/data \
chartmuseum/chartmuseum:latest检查确定安装成功
helm repo list
NAME URL
local http://127.0.0.1:8879/charts
stable http://chartmuseum:chartmuseum@172.16.16.21:8088执行helm init 初始化
helm init --stable-repo-url=http://chartmuseum:chartmuseum@172.16.16.21:8088 --tiller-image=index.alauda.cn/claas/tiller:v2.11.0添加相关权限
kubectl create serviceaccount --namespace kube-system tiller
kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller等待tiller pod启动
kubectl get pods --all-namespaces |grep tiller检查helm安装成功
helm version
Client: &version.Version{SemVer:"v2.11.0", GitCommit:"2e55dbe1fdbxxxxxxxxxxxx44a339489417b146b", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.11.0", GitCommit:"2e55dbe1fdbxxxxxxxxxxxx44a339489417b146b", GitTreeState:"clean"}部署prometheus
创建所需要的secret
kubectl -n alauda-system create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt修改配置
kube-scheduler:在各master节点上,编辑
vi /etc/kubernetes/manifests/kube-scheduler.yaml将其中的“–address=127.0.0.1”,替换为“–address=0.0.0.0”,保存退出
kube-controller-manager:在各master节点上,编辑
vi /etc/kubernetes/manifests/kube-controller-manager.yaml将其中的“–address=127.0.0.1”,替换为“–address=0.0.0.0”,保存退出
kube-proxy: 编辑cm kube-proxy
kubectl edit -n kube-system cm kube-proxy将“metricsBindAddress: 127.0.0.1:10249”替换为“metricsBindAddress: 0.0.0.0:10249”,保存退出;并杀掉kube-proxy的pod
注: dockerd: ACE-2.3/ACP-1.4采用docker v1.12.6。这个版本的docker不支持metrics-addr功能,导致prometheus获取不到dockerd相关数据。则grafana关于docker状态获取不到。
安装prometheus-operator
helm install <stable>/prometheus-operator --namespace=alauda-system --name prometheus-operator --set global.registry.address=<registry> --timeout=3000注:
- –set global.registry.address=
是设置当前环境的registry地址 - stable 为helm repo list 命令执行后,列出来的某一个repo源的name(是name,不是url),此处可以不同过chart repo源下载安装,也可以将chart下载到master机器上,指定chart路径部署。
安装kube-prometheus
对接LocalVolume作为存储
给集群中的一个node添加 monitoring=enabled的label,用于local volume的调度,命令如下如下:
kubectl label --overwrite nodes <node hostname> monitoring=enabled在该node上创建以下目录用作持久化目录,保证空间 granafa 2G/prometheus 20G/alertmanager 1G,命令如下:
mkdir -p /var/lib/monitoring/{grafana,prometheus,alertmanager}如果要使用上述目录之外的其他目录,安装kube-prometheus指定以下参数即可(同样需要提前创建)
--set grafana.storageSpec.persistentVolumeSpec.local.path=<Your Path> --set prometheus.storageSpec.persistentVolumeSpec.local.path=<Your Path> --set alertmanager.storageSpec.persistentVolumeSpec.local.path=<Your Path>
对接StorageClass作为存储
在安装kube-prometheus指定以下参数即可
--set grafana.storageSpec.volumeClaimTemplate.spec.storageClassName=<sc name> # grafana对接现有的StorageClass --set prometheus.storageSpec.volumeClaimTemplate.spec.storageClassName=<sc name> # prometheus对接现有的StorageClass --set alertmanager.storageSpec.volumeClaimTemplate.spec.storageClassName=<sc name> # alertmanager对接现有的StorageClass
安装kube-prometheus
helm install stable/kube-prometheus --name kube-prometheus --namespace alauda-system --timeout=30000 \ --set global.platform=<ACE/ACP> \ --set prometheus.service.type=NodePort \ --set grafana.service.type=NodePort \ --set grafana.crd.accessUrl=http://<ip> \ --set global.registry.address=<registry> \ --set deployKubeDNS=<true> --set deployCoreDNS=<false> \ --set alertmanager.configForACE.global.http_config.basic_auth.username=<username> \ --set alertmanager.configForACE.global.http_config.basic_auth.password=<password> \ --set alertmanager.configForACE.receivers[0].name=default-receiver \ --set alertmanager.configForACE.receivers[0].webhook_configs[0].url=<http://118.24.232.56:20081/v1/alerts/region_name/router> \ --set exporter-dockerd.endpoints=<dockerd host ip> # 以下参数均是可选的,如果你确认要修改这些配置可以加上这些参数,否则请不要随意设置这些参数 --set exporter-node.resources.requests.memory=300Mi \ --set exporter-node.resources.limits.memory=500Mi- –set global.platform=<ACE/ACP>是设置当前环境是ACP还是ACE【ACP/ACE二者选其一】
- –set global.registry.address=
是设置当前环境的registry地址【ACP/ACE均要设置】 - –set grafana.crd.accessUrl=http://
是设置ACP的grafana的访问地址 【ACP需要设置】 - –set deployKubeDNS=true –set deployCoreDNS=false如果部署的是kubedns,就像上述设置即可;如果dns是coredns,则需要设置–set deployKubeDNS=false –set deployCoreDNS=true【ACP/ACE均要设置】
- –set alertmanager.configForACE.global.http_config.basic_auth.username=
是设置登录Global平台的用户名【ACE需要设置】 - –set alertmanager.configForACE.global.http_config.basic_auth.password=
是设置登录Global平台的密码【ACE需要设置】 - –set alertmanager.configForACE.receivers[0].webhook_configs[0].url=http://118.24.232.56:20081/v1/alerts/region_name/router是设置alertmanager的Webhook的地址,其中118.24.232.56:20081是当前环境的jakiro的地址,region_name是当前私有区的名字【ACE需要设置】
- –set exporter-dockerd.endpoints=
是指定有dockerd主机上ip地址,不然检测不到相关主机上的dockerd的metrics,参数示例:{10.0.96.19,10.0.96.22,10.0.96.33,10.0.96.30,10.0.96.40,10.0.96.42}(有两个以上的机器时,注意格式,前面的ip后面要加) - –set exporter-node.resources.requests.memory=<300Mi>设置node-exporter的resource requests【可选,ACP/ACE均可选配置】
- –set exporter-node.resources.limits.memory=<500Mi>设置node-exporter的resource limits【可选,ACP/ACE均可选配置】
检查pod
# kubectl get pods -n alauda-system
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-0 2/2 Running 0 2h
kube-prometheus-exporter-kube-state-78b57fd848-gmsc7 2/2 Running 0 2h
kube-prometheus-exporter-node-7klhv 1/1 Running 0 2h
kube-prometheus-exporter-node-xsx5g 1/1 Running 0 2h
kube-prometheus-grafana-f95c87485-79zt5 3/3 Running 0 2h
prometheus-kube-prometheus-0 3/3 Running 1 2h
prometheus-operator-6dd688ff7f-gd4px 1/1 Running 0 2h检查kubelet的配置文件
找到配置文件
systemctl status kubelet kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2019-02-28 11:33:42 CST; 3 weeks 1 days ago Docs: http://kubernetes.io/docs/ Main PID: 21723 (kubelet)添加以下内容(如果有可不添加)
vim /etc/systemd/system/kubelet.service [Service] Environment="KUBELET_AUTHZ_ARGS=--authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt --authentication-token-webhook=true"重启kubelet
systemctl daemon-reload systemctl restart kubelet检查kubelet可以正常启动
system status kublet
访问Grafan/Prometheus
grafana
kubernetes集群中任何一个节点的ip:30902
prometheus
kubernetes集群中任何一个节点的ip:30900,默认用户名和密码为: admin/admin
删除prometheus
删除 kube-prometheus
helm delete --purge kube-prometheus kubectl delete pvc -n alauda-system prometheus-kube-prometheus-db-prometheus-kube-prometheus-0 kubectl delete pvc -n alauda-system alertmanager-kube-prometheus-db-alertmanager-kube-prometheus-0删除 prometheus-operator
helm delete --purge prometheus-operator kubectl delete --ignore-not-found customresourcedefinitions alertmanagers.monitoring.coreos.com prometheuses.monitoring.coreos.com prometheusrules.monitoring.coreos.com servicemonitors.monitoring.coreos.com
集群对接Prometheus监控
集成中心添加PrometheusOperator 类型的特性
进入”管理视图”,打开”集成中心”,选择”特性”栏,进入”添加集成”页面
选择 场景”特性”,类型”PrometheusOperator”
填写PrometheusOPerator有关集成信息
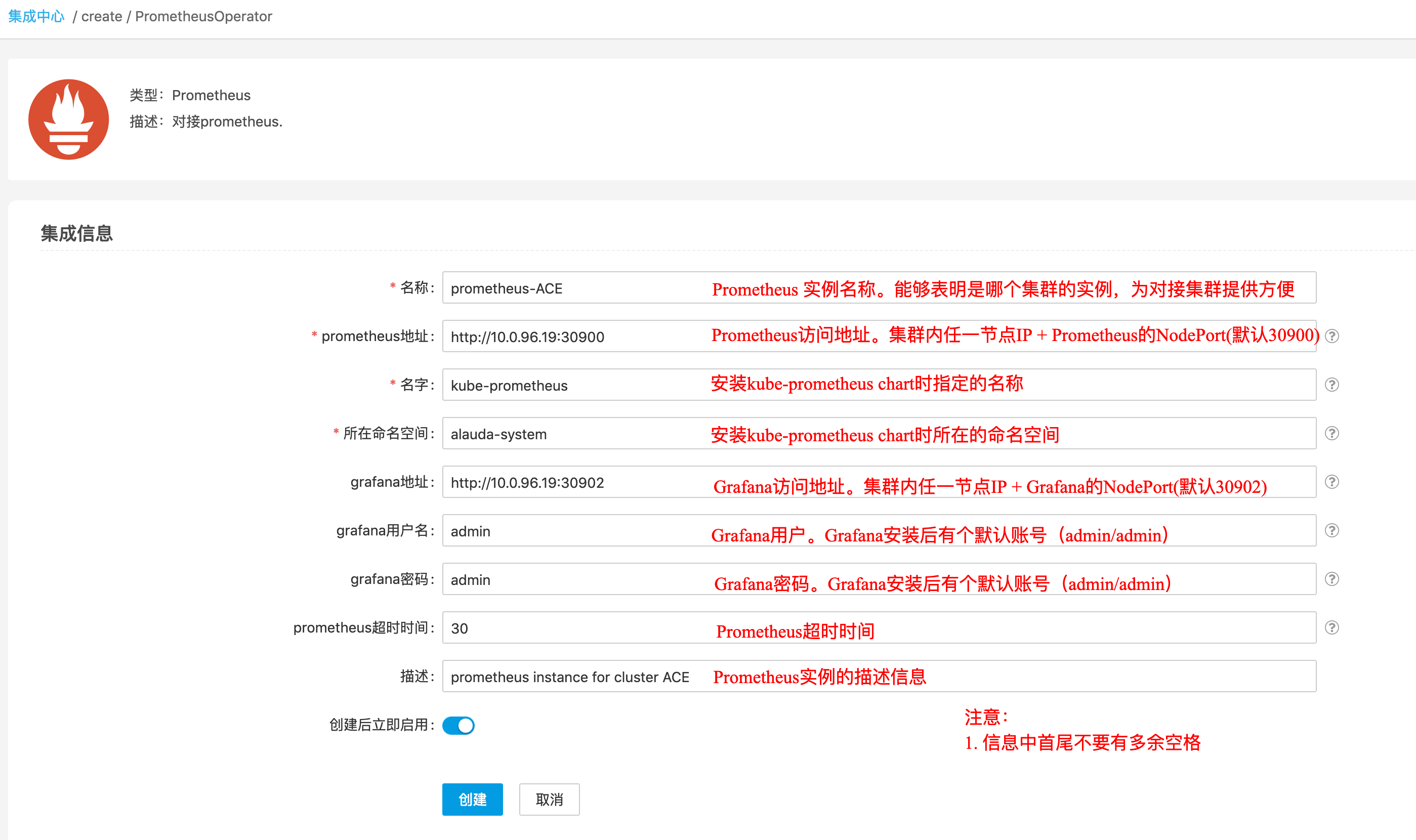
点击”创建”后,完成Prometheus集成实例的创建
集群对接Prometheus监控服务
- 进入”管理视图”,进入对应的集群。并依次点击”操作”、”集群特性管理”,进入”集群特性管理”页面
- 进入集群特性管理页面,查看”监控服务”,点击”对接第三方”。选择对应的Prometheus实例
- 查看集群相关的Cluster、Node、应用有监控数据出现
